This post covers the basics of Apache Parquet, which is an important building block in big data architecture. To learn more about managing files on object storage, check out our guide to Partitioning Data on Amazon S3.
In last year’s Amazon re:Invent conference (when real-life conferences were still a thing), AWS announced data lake export – the ability to unload the result of a Redshift query to Amazon S3 in Apache Parquet format. In the announcement, AWS described Parquet as “2x faster to unload and consumes up to 6x less storage in Amazon S3, compared to text formats”. Converting data to columnar formats such as Parquet or ORC is also recommended as a means to improve the performance of Amazon Athena.
It’s clear that Apache Parquet plays an important role in system performance when working with data lakes. Let’s take a closer look at what Parquet actually is, and why it matters for big data storage and analytics.
The Basics: What is Apache Parquet?
Apache Parquet is a file format designed to support fast data processing for complex data, with several notable characteristics:
1. Columnar: Unlike row-based formats such as CSV or Avro, Apache Parquet is column-oriented – meaning the values of each table column are stored next to each other, rather than those of each record:
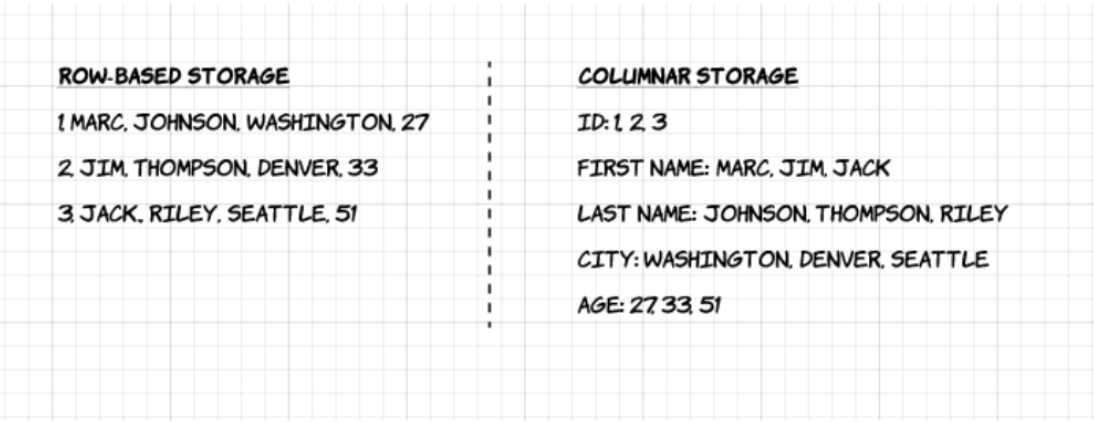
2. Open-source: Parquet is free to use and open source under the Apache Hadoop license, and is compatible with most Hadoop data processing frameworks.
3. Self-describing: In Parquet, metadata including schema and structure is embedded within each file, making it a self-describing file format.
Advantages of Parquet Columnar Storage
The above characteristics of the Apache Parquet file format create several distinct benefits when it comes to storing and analyzing large volumes of data. Let’s look at some of them in more depth.
Compression
File compression is the act of taking a file and making it smaller. In Parquet, compression is performed column by column and it is built to support flexible compression options and extendable encoding schemas per data type – e.g., different encoding can be used for compressing integer and string data.
Parquet data can be compressed using these encoding methods:
- Dictionary encoding: this is enabled automatically and dynamically for data with a small number of unique values.
- Bit packing: Storage of integers is usually done with dedicated 32 or 64 bits per integer. This allows more efficient storage of small integers.
- Run length encoding (RLE): when the same value occurs multiple times, a single value is stored once along with the number of occurrences. Parquet implements a combined version of bit packing and RLE, in which the encoding switches based on which produces the best compression results.

Performance
As opposed to row-based file formats like CSV, Parquet is optimized for performance. When running queries on your Parquet-based file-system, you can focus only on the relevant data very quickly. Moreover, the amount of data scanned will be way smaller and will result in less I/O usage. To understand this, let’s look a bit deeper into how Parquet files are structured.
As we mentioned above, Parquet is a self-described format, so each file contains both data and metadata. Parquet files are composed of row groups, header and footer. Each row group contains data from the same columns. The same columns are stored together in each row group:
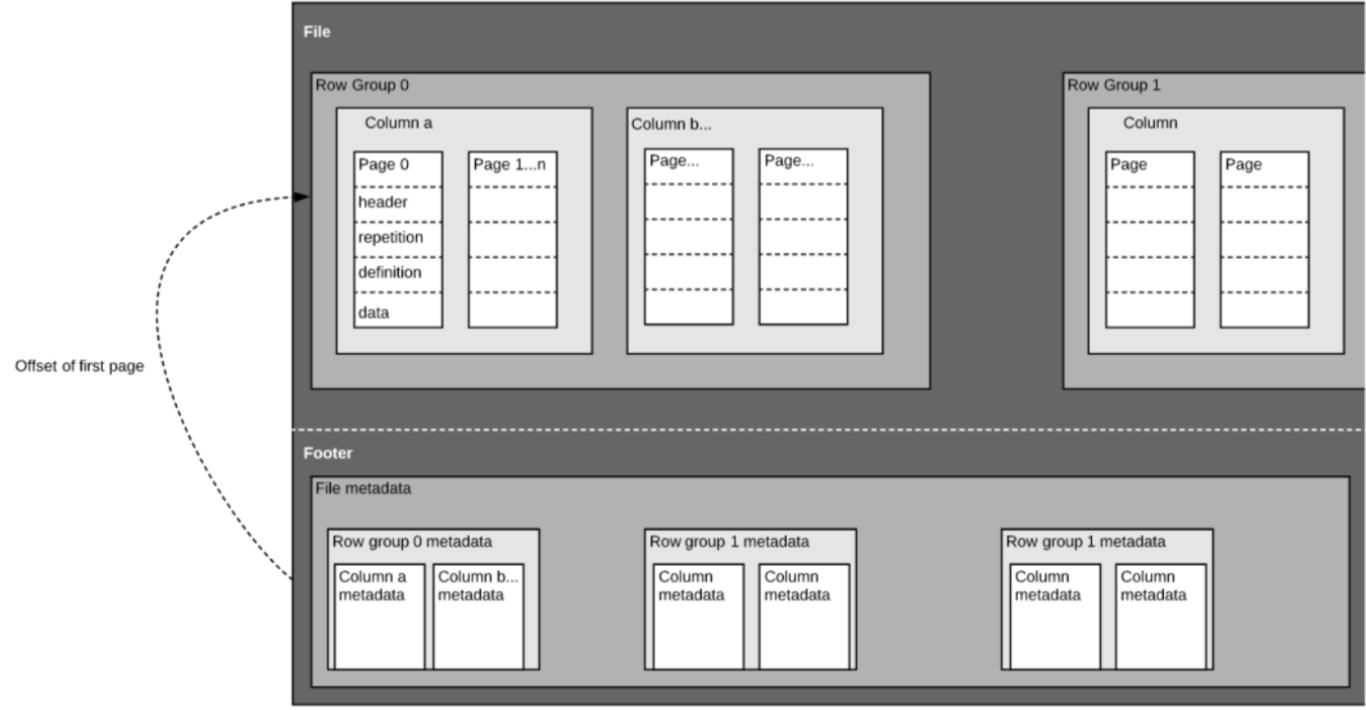
This structure is well-optimized both for fast query performance, as well as low I/O (minimizing the amount of data scanned). For example, if you have a table with 1000 columns, which you will usually only query using a small subset of columns. Using Parquet files will enable you to fetch only the required columns and their values, load those in memory and answer the query. If a row-based file format like CSV was used, the entire table would have to have been loaded in memory, resulting in increased I/O and worse performance.
Schema evolution
When using columnar file formats like Parquet, users can start with a simple schema, and gradually add more columns to the schema as needed. In this way, users may end up with multiple Parquet files with different but mutually compatible schemas. In these cases, Parquet supports automatic schema merging among these files.
Open-source support
Apache Parquet, as mentioned above, is part of the Apache Hadoop ecosystem which is open-source and is being constantly improved and backed-up by a strong community of users and developers. Storing your data in open formats means you avoid vendor lock-in and increase your flexibility, compared to proprietary file formats used by many modern high-performance databases. This means you can use various query engines such as Amazon Athena, Qubole, and Amazon Redshift Spectrum, within the same data lake architecture.
Column-oriented vs row based storage for analytic querying
Data is often generated and more easily conceptualized in rows. We are used to thinking in terms of Excel spreadsheets, where we can see all the data relevant to a specific record in one neat and organized row. However, for large-scale analytical querying, columnar storage comes with significant advantages with regards to cost and performance.
Complex data such as logs and event streams would need to be represented as a table with hundreds or thousands of columns, and many millions of rows. Storing this table in a row based format such as CSV would mean:
- Queries will take longer to run since more data needs to be scanned, rather than only querying the subset of columns we need to answer a query (which typically requires aggregating based on dimension or category)
- Storage will be more costly since CSVs are not compressed as efficiently as Parquet
Columnar formats provide better compression and improved performance out-of-the-box, and enable you to query data vertically – column by column.
Example: Parquet, CSV and Amazon Athena
We’re exploring this example in far greater depth in our upcoming webinar with Looker. Save your spot here.
To demonstrate the impact of columnar Parquet storage compared to row-based alternatives, let’s look at what happens when you use Amazon Athena to query data stored on Amazon S3 in both cases.
Using Upsolver, we ingested a CSV dataset of server logs to S3. In a common AWS data lake architecture, Athena would be used to query the data directly from S3. These queries can then be visualized using interactive data visualization tools such Tableau or Looker.
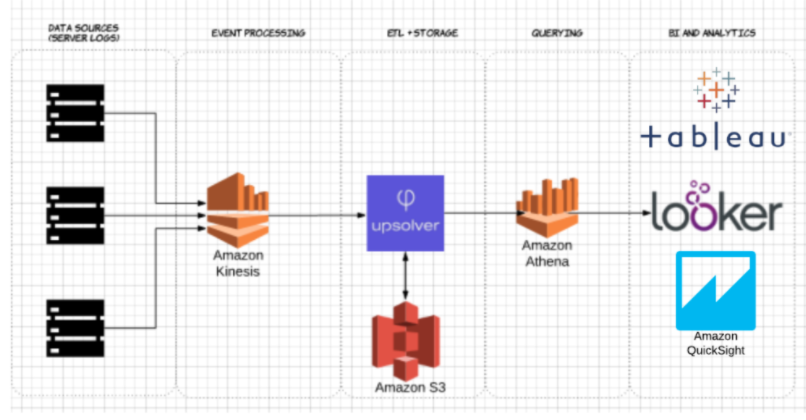
We tested Athena against the same dataset stored as compressed CSV, and as Apache Parquet.
This is the query we ran in Athena:
SELECT tags_host AS host_id, AVG(fields_usage_active) as avg_usage
FROM server_usage
GROUP BY tags_host
HAVING AVG(fields_usage_active) > 0
LIMIT 10
And the results:
| CSV | Parquet | Columns | |
| Query time (seconds) | 735 | 211 | 18 |
| Data scanned (GB) | 372.2 | 10.29 | 18 |
- Compressed CSVs: The compressed CSV has 18 columns and weighs 27 GB on S3. Athena has to scan the entire CSV file to answer the query, so we would be paying for 27 GB of data scanned. At higher scales, this would also negatively impact performance.
- Parquet: Converting our compressed CSV files to Apache Parquet, you end up with a similar amount of data in S3. However, because Parquet is columnar, Athena needs to read only the columns that are relevant for the query being run – a small subset of the data. In this case, Athena had to scan 0.22 GB of data, so instead of paying for 27 GB of data scanned we pay only for 0.22 GB.
Is using Parquet enough?
Using Parquet is a good start; however, optimizing data lake queries doesn’t end there. You often need to clean, enrich and transform the data, perform high-cardinality joins and implement a host of best practices in order to ensure queries are consistently answered quickly and cost-effectively.
You can use Upsolver to simplify your data lake ETL pipeline, automatically ingest data as optimized Parquet and transform streaming data with SQL or Excel-like functions. To learn more, schedule a demo right here.

No comments:
Post a Comment