In this section, we will see different clients
available as part of DataStage installation and how to connect to them and
explore various options and features available.
Connecting to DataStage Clients:
First let us see how to connect to
DataStage and see various parameters required for logging in.
If you do not already have a connection
to DataStage from your PC then you will need to connect your DataStage client
to the DataStage server. Find the client that you wish to connect, perhaps from
a desktop shortcut, perhaps from the Start menu. This invokes the Attach
to Project dialog, illustrated here.

Within that dialog you must supply the
host name or IP address of the machine on which the DataStage server is running
(the Metadata/App Server hostname), the login ID and password that
authenticates you to that machine, then choose the project in which you wish to
work from the drop-down list. The Project name is a combination of the
DataStage Server name and the actual DataStage Project name. In this
illustration, the DataStage Server name and Metadata Server name are both same,
this is because, both are installed on same machine. They will differ, if the
App Server and DataStage engine are split between different servers or if there
are additional DataStage engines hosted on different servers and you wish to
connect to the additional server.
If you have previously successfully
connected to a DataStage project, the host system, user name and Project fields
are pre-populated with values from that connection. You must, of course,
re-enter your password.
If you already have a connection to
DataStage from your PC using Designer, Director, then you can open other client
tools from that client’s Tools menu.
DataStage Developer Clients:
DataStage Designer:
The Designer client is where you create
and compile jobs. It is also possible to run jobs from Designer, though
mainframe jobs cannot be run from Designer. Server jobs may be run in debug
mode in Designer. It acts as a browser into the Repository, the database
associated with a project.

Designer Client can be used to import
table definitions from various sources as well as DataStage components exported
from any project (provided that it’s not at a higher version number). You
can also create some kinds of components, such as Data Elements and Routines,
and edit the properties of an extant object.
Designer Client is the graphical user
interface in which you draw the pictures, using stages and links, of the data
flow that you wish to implement, and then fill in the details by editing the
properties of the job, the stages and the links to make the design absolutely
specific about what you intend to happen.
It is in the Designer, too, that you
compile the job design to produce executable code; in the case of parallel jobs
this will primarily be OSH script, but may also include some generated C++
code. In the case of job sequences the code generated will be DataStage
BASIC. In both cases, you are able to inspect the generated code. This will
be covered in more detail later.
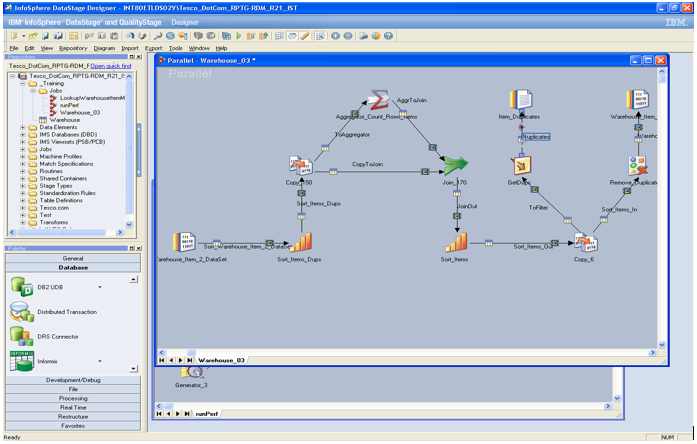
Here we see the Designer client
illustrated. In its title bar are shown the server identity and the name
of the project to which the Designer is connected. On the left hand side there
is the Palette, from which components can be added to the job design, and a
browser into the Repository. There is a standard menu and standard toolbar
across the top. In the right hand pane there are at least two job designs
open; the one on top is a parallel job called Warehouse_03 (from its title
bar). * Mark on the title bar of the job indicates it is under editing.
The job design itself consists of a
number of stages (icons) connected to each other by links (arrows) that
indicate the flow of data in the design. Links painted as long dashed lines in
this design handle rows that are rejected within the job design, either because
of metadata mismatch or because of a failed condition. Because the stages
and links follow a standard naming convention, it is even easier to understand
what is intended.
Designer Toolbars: There are, indeed, more toolbars in
Designer than were visible in the previous illustration. There are five
in all, listed here – Standard, Palette, Repository, Property Browser, and
Debug Bar.

All but the last toolbar are visible for
all job types; the Debug bar is only enabled for server jobs.
These toolbars are all illustrated on the
above image, which shows a server job rather than a parallel job (so that the
Debug bar can be rendered visible).
Every toolbar in Designer floats, as can
be seen with the Property Browser in this illustration.
Each toolbar can be anchored against any
side of the window. In this illustration the standard and Debug bars are
anchored at the top, while the Palette and Repository toolbars are anchored
against the left hand side of the Designer window. Every toolbar can be hidden
(closed), and rendered visible again via the View menu.
DataStage Repository:
As said earlier, we can render visible
Repository window in DataStage Designer, This Repository toolbar is a browser
into the Repository of the selected project. It has a Windows Explorer
look and feel. One view is repository view showing the major branches in the
Repository. Second one contains a detailed view, but only if a leaf node
of the tree view is selected. In Detail view, short descriptions and date/time
modified are displayed. If used wisely these can aid selection of the correct
component.
You can use the Repository tree to browse
and manage objects in the repository.
The Designer enables you to store the
following types of object in the repository (listed in alphabetical order):
·
Data connections
·
Data elements
·
IMS™ Database (DBD)
·
IMS Viewset (PSB/PCB)
·
Jobs
·
Machine profiles
·
Match specifications
·
Parameter sets
·
Routines
·
Shared containers
·
Stage types
·
Table definitions
·
Transforms
When you first open IBM InfoSphere
DataStage you will see the repository tree organized with preconfigured folders
for these object types, but you can arrange your folders as you like and rename
the preconfigured ones if required. You can store any type of object within any
folder in the repository tree. You can also add your own folders to the tree.
This allows you, for example, to keep all objects relating to a particular job
in one folder. You can also nest folders one within another.
Note: Certain built-in objects cannot be moved in
the repository tree
Click the blue bar at the side of the
repository tree to open the detailed view of the repository. The detailed view
gives more details about the objects in the repository tree and you can
configure it in the same way that you can configure a Windows Explorer view.
Click the blue bar again to close the detailed view.
You can view a sketch of job designs in
the repository tree by hovering the mouse over the job icon in the tree. A
tooltip opens displaying a thumbnail of the job design. (You can disable this
option in the Designer Options.)
When you open an object in the repository
tree, you have a lock on that object and no other users can change it while you
have that lock (although they can look at read-only copies).

In this illustration of Repository, there
are a few points to note.
The name of the host machine and the name
of the project are displayed in the title bar. You always know in which
project you are working. The tree view is expanded on the Stage Types
branch. Because the selected branch is as fully expanded as it can be (that
is, a leaf node is selected), the right-hand pane contains a list of the
elements that belong in that particular category. In this illustration, the
category is Parallel\Database.
Currently detail view is selected, which
means that the individual descriptions of the stage types are displayed.
This makes choosing the appropriate component easier, as you have more
information available. It is possible to view more information about each
object by customizing detailed view. To do this, right-click on header (say,
Name) and select more, a pop-up shows up displaying what all properties you can
select. Please see the properties that you select will be visible in this list
view and in the export window while you export jobs from Repository.
Major Categories:
Not all the categories shown in the
previous illustration will be available. For example, the IMS Databases
and IMS Viewsets categories are only available if IMS is licensed, and the
Machine Profiles category is only available if the mainframe edition is
licensed. No matter which edition is licensed, the seven major categories
listed here are always available. These will be covered in greater detail
later; for now here is a quick summary.
·
Data
Elements are
like user-defined data types that more precisely describe data classes (for
example CustomerID, TelephoneNumber).
·
Jobs are executable units. Properties of
existing can be accessed, jobs must be edited in Designer.
·
Routines are custom transform BASIC
functions, before/after subroutines, interludes to external parallel routines,
or references to mainframe routines.
·
Shared
Containers are a
mechanism for making subsets of job designs reusable in more than one job.
·
Stage
Types are
the classes from which stages in job designs are instantiated.
·
Table
Definitions are
collections of column definitions and any other associated information about
persistent data (for example format of sequential file, owner of database
table).
·
Transforms are pre-stored, and therefore re-usable,
BASIC expressions. They can only be used in server jobs and parallel job BASIC
Transformer stages.
Connecting to another Client
If you have one of the two clients
(Designer or Director) open, you can connect to one of the other clients by
opening the Tools menu. On this menu you will find options to Run the
other clients. For example, from Director, the option is Run Designer.
From Designer, it is Run Director.
Taking this path means that your current
authentication can be re-used so that you do not need to enter user ID or
password, or choose a project to which to connect.
DataStage Director Client
The Director client can be used to run
jobs straight away or to schedule them to be run at some future time(s). The
Director client is also used to determine the status of jobs, and to inspect
the logs that jobs
generated. Mainframe jobs are only run on
the mainframe machines, so there is no Director interaction with mainframe
jobs. The Director client can also be used to override project-default
job log purge parameters and to set run-time default values for job parameters.
The Director client has four different
views. Inside Director, one can see only Jobs in the Repository and not
other components.
·
Status view shows the most recently recorded status of
all jobs in the currently selected category. It is possible, through the View
menu, to disable the use of categories and thus to show all jobs in the project
but, as the project grows, populating this window will take longer and longer.
·
Log view shows the job log for the currently selected
job. The most recent run is shown in black, the previous run in dark blue, and
any earlier runs in a lighter blue.
·
Schedule view shows jobs in the currently selected
category and whether they have been scheduled (from DataStage) to run at some
time in the future. It is also possible to schedule jobs to run using
third-party scheduling tools, but these are not reported in the Schedule view
in Director.
·
Monitor view allows row counts for active stages and
their connected links to be displayed along with rows/second figures. CPU
consumption can also be reported.
Director – Status View
This is an illustration of Director’s
status view.

In the title bar are the identity (here,
IP address) of the DataStage server and the project to which Director client is
connected. In the status bar (at the bottom) are the count of jobs in the
currently selected category and, on the bottom right, the server time.
All times reported are the server time. This is very important for
offshore developers, for whom local time might be substantially different from
the server time.
Each job has its most recent status
displayed in the Status column. Also displayed are the most recent start
time, the most recent finished time and the corresponding elapsed time (rounded
to the nearest whole second) plus the description of the job (one of the job’s
properties).
Director – Log View
In Log view the name of the currently
selected job is reported in the status bar, along with the number of entries
visible (and the fact, here, that a filter is being used) and the server time.

Entries for the most recent run are in
black text; the previous run in dark blue. Green icons indicate informational
messages, yellow icons indicate warning messages (non-fatal), and red icons
indicate fatal errors, which caused the job to abort. You should aim to create
jobs that never produce anything but informational messages; thus, if a warning
occurs, something unexpected has occurred (and you can deal with it). Any
logged event that has a diaresis (…) at the end of its message contains more
text than is viewable in summary view. Double clicking an event (or
choosing Detail from the View menu) opens the Event Detail dialog, in which the
remainder of the message can be seen.
However, there is sufficient information
in this summary view to determine the cause of the problem (unable to create
file, indicating either a permissions problem or a missing directory).
This is the log of a server job; logs for parallel jobs tend to be more
verbose, as they potentially report from multiple processing nodes.
There is a short cut from Designer to the
job log; under the Debug menu there is an option to View Job Log (for Server
jobs).
Director – Schedule View
Schedule view (the clock icon fourth from
the left on the toolbar) shows any jobs that have been scheduled from the
Director client, along with the parameter values and/or descriptions associated
therewith. Jobs scheduled from the Director use the operating system
scheduler (AT on Windows, cron or at on UNIX).
Note: Most projects use third party
schedulers like Ctrl-M, AutoSys for scheduling DataStage jobs.
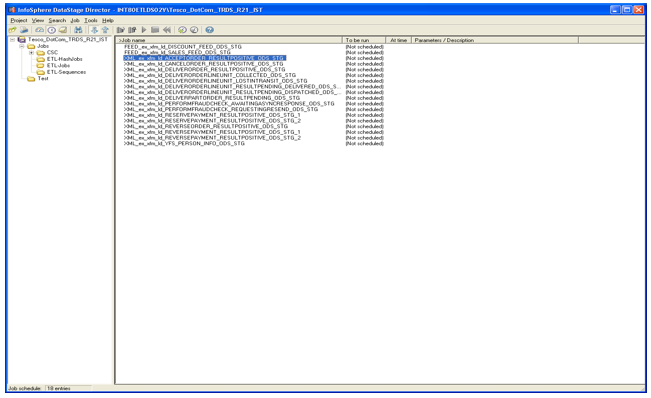
Director – Job Monitor
Use the monitor window to view summary information
about relevant stages in a job that is being run or validated.
The monitor window displays stages in a
job and associated links in a tree structure. For server jobs active stages are
shown (active stages are those that perform processing rather than ones reading
or writing a data source). For parallel jobs, all stages are shown.
The window has the following controls and
fields:
Stage name – For parallel jobs, this column displays
the names of all stages in the job. For server jobs, this column displays the
names of stages that perform processing (for example, Transformer stages).Link
Type
Link Type – When you have selected a link in the
tree, displays the type of link as follows:
<<Pri – stream input link
<Ref – reference input link
>Out – output link
>Rej – reject output link
Status – The status of the stage. The possible
states are:
·
Aborted – The process finished abnormally at this
stage.
·
Finished – All data has been processed by the stage.
·
Ready – The stage is ready to process the data.
·
Running – Data is being processed by the stage.
·
Starting – The processing is starting.
·
Stopped – The processing was stopped manually at this
stage.
·
Waiting – The stage is waiting to start processing.
·
Num rows – This column displays the number of rows of
data processed so far by each stage on its primary input.
·
Started at – This column shows the time that
processing started on the engine.
·
Elapsed time – This column shows the elapsed time
since processing of the stage began.
·
Rows/sec – This column displays the number of rows
that are processed per second.
·
%CP – The percentage of CPU the stage is using (you
can turn the display of this column on and off from the shortcut menu)
·
Interval – This option sets how often the window is updated
with information from the engine. Click the arrow buttons to increase or
decrease the value, or enter the value directly. The default setting is 10, the
minimum is 5, and the maximum is 65.
·
Job name – The name of the job that is being
monitored.
·
Status – The status of the job
·
Project – The name of the project and the computer
that is hosting the engine tier.
·
Server time – The current time on the computer that is
hosting the engine tier.
If you are monitoring a parallel job, and
have not chosen to view instance information, the monitor displays additional
information for Parallel jobs as follows:
·
If a stage is running in parallel, then x N is
appended to the stage name, where N gives how many instances are running.
·
If a stage is running in parallel then the Num Rows
column shows the total number of rows processed by all instances. The Rows/sec
is derived from this value and shows the total throughput of all instances.
·
If a stage is running in parallel then the %CP might
be more than 100 if there are multiple CPUs. For example, on a machine with
four CPUs, %CP could be as high as 400® where a stage is occupying 100% of each
of the four processors, alternatively, if the stage is occupying only 25% of
each processor the %CP would be 100%.
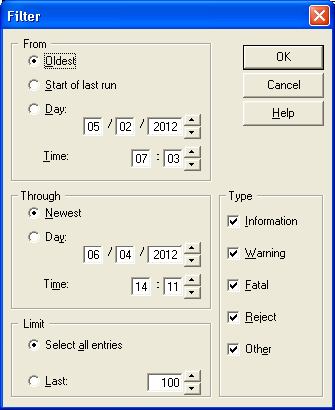
Filters in Director
Every view in Director has a filter.
Status and Schedule view allow you to filter on job name (you can use
wildcards) and on job status (for example you can select non-compiled jobs
only). Log view allows you to filter on event date and event severity (for
example omit informational messages). By default, Log view has a filter
that shows only the most recent 100 entries; if there are more entries in the
log than this, then a warning message box pops up when Log view is opened.
Monitor view filter allows %CPU to be selected or de-selected.In all views
(except Monitor) the filter dialog can be opened by pressing Ctrl-T, or by
right-clicking in the unused background area. In Monitor view only right
clicking in the background area works.
DataStage Administrator Client
The Administrator client is used primarily
to create and delete projects and, mainly for newly-created projects, to set
project-wide defaults, for example when job logs will automatically be purged
of old entries. These defaults apply only to objects created subsequently
in the project; changing a default value does not affect any existing objects
in the project.
The things that can be set in the
Administrator that relate specifically to parallel jobs are enabling runtime
propagation, setting environment variables and enabling visibility of generated
Orchestrate shell (OSH) scripts. It is also possible to specify advanced
command line options for OSH and default formats for date, time, timestamp and
decimal data types.
Connecting to Administrator
Invoke the Administrator client from the
Windows Start menu, or from a desktop shortcut. This brings up the Attach to
DataStage dialog, where you fill in the host name or IP address of the
Domain/Metadata Server (Services Tier), the login ID and password of an
administrative user that has permission to configure projects and host name of
Information Server Engine

Once
authentication details are supplied, clicking OK invokes the “InfoSphere DataStage Administration –
<ServerEngine>”dialog.
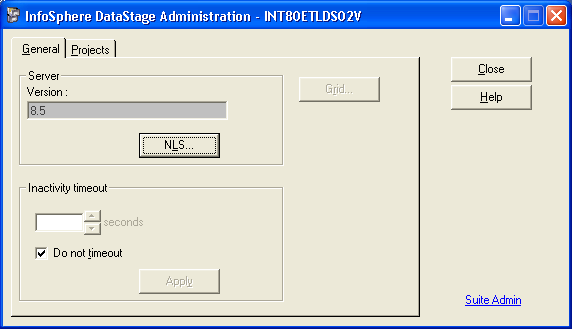
On
the General tab information about the server version is displayed; if NLS is enabled it can be configured, and a
client/server inactivity timeout can be configured.
“Suite Admin” takes you to
Information Server Web Console.
Grid support is available if at least one
project is configured to run parallel jobs on a Grid.
Projects Tab:
The Projects tab displays a list of projects
currently defined on the server, and provides means for adding and deleting
projects, executing a command in a project, and a button called Properties that
invokes the Project Properties dialog, shown in next slide.
The controls and buttons on the Projects
page are as follows:
·
Project
list: The
main window lists all the projects that exist on the Information Server engine.
·
Project
pathname: The
path name of the project currently selected in the Project list.
·
Add: Click this to add a new project, the
Add Project dialog box opens. This button is enabled only if you have
administrator status.
·
Delete: Click this to delete the project
currently selected in the Project list. This button is enabled only if you have
administrator status.
·
Properties: Click this to view the properties of
the project currently selected in the Project list. The Project Properties
dialog box opens.
·
NLS: Click this to open the Project NLS
Settings dialog box.
·
Command: Click this to open the Command Interface
dialog box which you can use to issue commands to the InfoSphere Information
Server engine that you are administering.
Suite Admin: Click this to open the Suite
Administrator tool in a browser window. Use the Suite Administrator tool to
perform common Administrator tasks associated with the suite server backbone.

Project Properties
When we choose a Project and click on the
Properties button shown in the previous slide, Project Properties dialog gets
invoked as shown here.
·
Enable
job administration in Director: Click this to enable the Cleanup Job
Resources and Clear Status File commands in the Job menu in the InfoSphere™
DataStage® Director. Setting this option also enables the Cleanup Job Resources
command in the Monitor window shortcut menu in the Director.
·
Enable
Runtime Column Propagation for Parallel Jobs: If you enable this feature, parallel
jobs can handle undefined columns that they encounter when the job is run, and
propagate these columns through to the rest of the job. Be warned, however,
that enabling runtime column propagation can result in very large data sets.
Selecting this option makes the following
subproperty available:
·
Enable
Runtime Column Propagation for new links: Select this to have runtime column
propagation enabled by default when you add a new link in an InfoSphere
DataStage job. If you do not select this, you will need to enable it for
individual links in stage editors when you are designing the job.
Enable editing of internal references in jobs: Select this to enable the editing of the
Table definition reference and Column definition reference fields in the column
definitions of stage editors. You can only edit the fields in the Edit Column
Metadata dialog box, or by column propagation. The Table definition reference
and Column definition reference fields identify the table definition and
individual columns within that definition that columns have been, that columns
have been loaded from. These fields are enabled on the stage editor’s Columns
tab via the Grid Properties dialog box.

·
Share
metadata when importing from connectors: This option is
selected by default. When metadata is imported using a connector, then the
metadata appears in both the shared repository and the project repository.
·
Protect
project: Click
this to protect the current project. This button is only enabled if you have
production manager status. If the project is already protected the button says
Unprotect project and you can click it to convert the project back to an
ordinary one (again you must have Production Manager Status to do this. (Note
that, on UNIX systems, only root or the administrative user can currently
protect and unprotect projects).
·
Environment: Click this to open the Environment Variables
dialog box. This enables you to set project-wide default values for environment
variables.
·
Generate
operational metadata: Select this option to have parallel and server jobs
in the project generate operational metadata by default. You can override this
setting in individual jobs if required.
Environment Variables
Click on Environment to open Environment
Variables dialog box. Here, we can set project-wide defaults for general environment
variables or ones specific to parallel jobs. You can also specify new
variables. All of these are then available to be used in jobs.
Parallel jobs – or, more precisely, the
parallel engine – make extensive use of environment variables. Names beginning
with “APT_” are related to the parallel engine or to operators that it
invokes. This dialog also allows a developer to create user defined
environment variables that might, for example, subsequently be used to provide
values to job parameters.
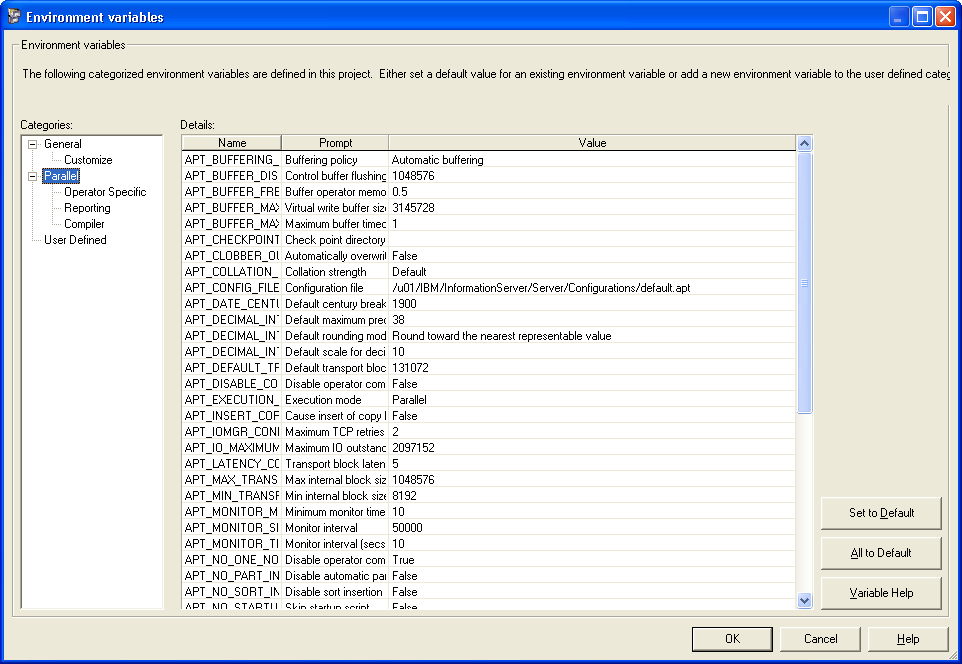
Don’t change any environment variables
without seeking advice on the likely impact of doing so. If you need to define
additional environment variables this will generally be OK, but still seek
advice until you have a little more experience.
Permissions Page
Before any user can access InfoSphere
DataStage they must be defined in the Suite Administrator tool as a DataStage
Administrator or a DataStage User. As a DataStage administrator you can define
whether a DataStage user can access a project, and if so, what category of
access they have. If you want to add DataStage Developers, DataStage Operators,
or DataStage Super Operators to a project, these users must be assigned the
DataStage User role in the Suite Administrator tool. If they have the DataStage
Administrator role they will automatically have administrator privileges and
you cannot restrict their access in the Permissions page.

Using the Suite Administrator tool you
can also add groups and assign users to groups. These groups are in turn
allocated the role of DataStage Administrator or DataStage User. Any users
belong to an administrator group will be able to administer InfoSphere
DataStage. As a DataStage Administrator you can give a DataStage user group
access to a project and assign a role to the group.
When setting up users and groups, these
still have to have the correct permissions at the operating system level to
access the folders in which the projects reside.
You can also change the default view of
job log entries for those who have the DataStage Operator or DataStage Super
Operator role.
The Permissions page contains the
following controls:
Roles: This window lists all the users and groups
who currently have access to this project and lists their roles. Note that this
window will always include users who have been defined as DataStage
Administrators in the Suite Administrator tool, and you cannot remove such
users from the list or alter their user role.
User Role: This list contains the four categories of
InfoSphere DataStage user you can assign. Choose one from the list to assign it
to the user currently selected in the roles window.
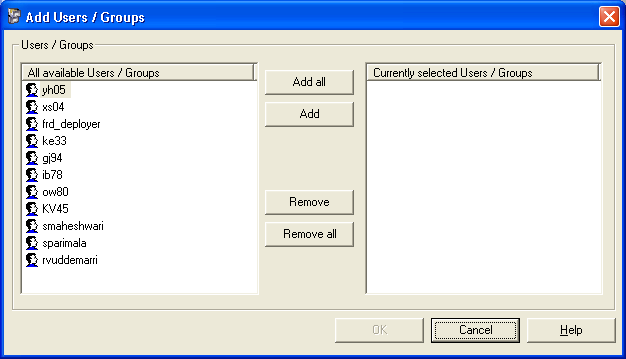
Add User or Group: Click this to open the Add Users/Groups
dialog box in order to add a new user or group to the ones listed in the roles
window.
Remove: Click this to remove the selected user or
group from those listed in the roles window.
DataStage Operator can view full log: By default this check box is selected,
letting an InfoSphere DataStage operator view both the error message and the
data associated with an entry in a job log file. To hide the data part of the
log file entry from operators, clear this check box. Access to the data is then
restricted to users with a developer role or better.
In
the above dialog, choose “Add User or Group”. This displays available
users/groups on the left hand side and selected users on the right hand side.
Similarly, it is possible to remove a user or a group.
Tracing Page
Use the Tracing page to trace activity on
the InfoSphere™ Information Server engine. This can help to diagnose project
problems.
The page contains the following controls:
Enabled: Enables tracing on the engine.
Information that might help to identify the cause of a client problem is stored
in trace files. To interpret this information you will require in-depth
knowledge of the system software.
Trace files: Lists the trace files to which
information about engine activity is sent.
View: Click this to display the trace file
selected in the Trace files list.
Delete: Click this to delete the trace files
selected in the Trace files list.

Tunable Page
Use the Tunables page to set cache
parameters for Hashed File stages and to enable row buffering in server jobs.
When a Hashed File stage writes records to a hashed file, there is an option
for the write to be cached rather than written to the hashed file immediately.
Similarly, when a Hashed File stage is reading a hashed file there is an option
to pre-load the file to memory, which makes subsequent access very much faster
and is used when the file is providing a reference link to a Transformer stage.
(UniData stages also offer the option of pre-loading files to memory, in which
case the same cache size is used). The Hashed file stage area of the Tunables
page lets you configure the size if the read and write caches.

The page contains the following controls:
Read cache size (MB): Specify the size of the read cache in
Megabytes. The default is 128.
Write cache size (MB): Specify the size of the write cache in
Megabytes. The default is 128.
Enable row buffer: The use of row buffering can greatly enhance
performance in server jobs. Select this check box to enable this feature for
the whole project. The following option buttons are then enabled:
In-process: In-process row buffering allows connected
active stages to pass data via data buffers rather than row by row. Choosing
this type of row buffering will improve the performance of most server jobs.
Note that you cannot use in-process row buffering if your jobs currently use
COMMON blocks to pass data between stages. This is not recommended practice and
it is advisable to redesign your job to use row buffering rather than COMMON
blocks.
Inter-process: Use this if you are running server jobs
on a SMP parallel system. This enables the job to run using a separate process
for each active stage, which can then run simultaneously on separate processes.
Note that you cannot use inter-process row buffering if your jobs currently use
COMMON blocks to pass data between stages. This is not recommended practice and
it is advisable to redesign your job to use row buffering rather than COMMON
blocks.
Buffer size: Specifies the size of the buffer used by
in-process or inter-process row buffering. Defaults to 128 Kilobytes.
Timeout: Only applies when inter-process row
buffering is used. Specifies the time one process will wait to communicate with
another via the buffer before timing out. Defaults to 10 seconds.
Parallel Page
On the Parallel tab are three main areas.
The check box allows generated
Orchestrate shell (OSH) to be visible. This can be useful to have when troubleshooting/debugging.
The advanced runtime options allows
additional command options to be specified that govern the way in which
parallel jobs execute at run time.
The format defaults will generally be
left at system default. If ever you have problems with formats, you will
probably need to set up some kind of job-specific or stage-specific override,
cast or transformation to re-format that particular item of data into the
expected format.
Use the Parallel page to set certain
parallel job properties and to set defaults for date/time and number formats.
The page contains the following controls:
Enable grid support for parallel jobs: Select this option to run the jobs in
this project in a grid system, under the control of a resource manager. If you
select this option on non-grid systems, you can design jobs suitable for
deployment on a grid system.
Grid: Click Grid to open the Static resource
configuration for grid window. Use this window to specify which static
resources are available to be allocated for job runs on a grid system. Static
resources include fixed-name servers such as database servers, SAN servers, SAS
servers, and remote storage disks. The grid is populated from a master
configuration file, and you can use this window to select which of the resources
defined in the master configuration file are available to the jobs in your
project.
Generated OSH visible for Parallel jobs in ALL projects: If you enable this, you will be able to
view the code that is generated by parallel jobs at various points in the
Designer and Director:
·
In the Job Properties dialog box for parallel jobs.
·
In the job run log message.
·
When you use the View Data facility in the Designer.
·
In the Table Definition dialog box.
Note that selecting this option enables this
feature for all projects, not just the one currently selected.
Advanced runtime options for Parallel Jobs: This field allows experienced Orchestrate
users to enter parameters that are added to the OSH command line. Under normal
circumstances this should be left blank. You can use this field to specify the
-nosortinsertion and the -nopartinsertion options. These prevent the automatic
insertion of sort and partition operations where InfoSphere™ DataStage®
considers they are required. This applies to all jobs in the project.
Message Handler for Parallel Jobs: Allows you to specify a message handler
for all the parallel jobs in this project. You define message handlers in the
InfoSphere DataStage Designer or Director. They allow you to specify how
certain warning or information messages generated by parallel jobs are handled.
Choose one of the predefined handlers from the list.
Format defaults: This area allows you to override the
system default formats for dates, times, timestamps, and decimal separators. To
change a default, clear the corresponding System default check box, then either
select a new format from the drop down list or type in a new format.
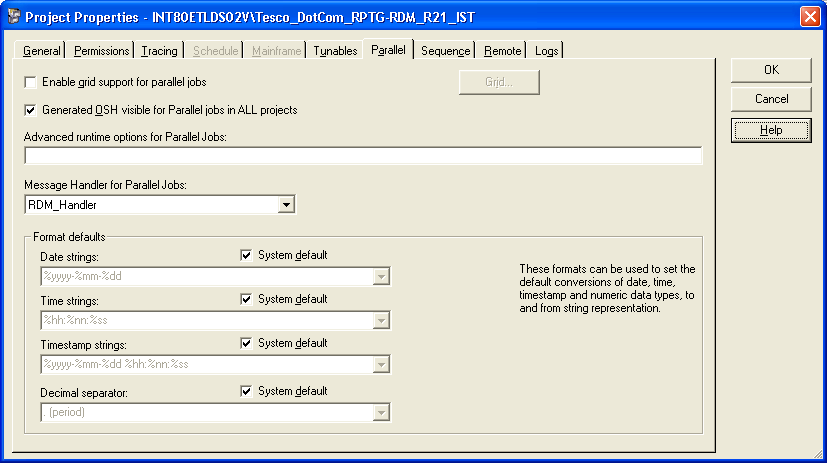
Sequence Page
Use this page to set compilation defaults
for job sequences. You can optionally have InfoSphere™ DataStage® add
checkpoints to a job sequence so that, if part of the sequence fails, you do
not necessarily have to start again from the beginning. You can fix the problem
and rerun the sequence from the point at which it failed. You can also specify
that InfoSphere DataStage automatically handle failing jobs within a sequence
(this means that you do not have to have a specific trigger for job failure).

The page contains the following controls:
Add checkpoints so sequence is restartable on failure: Select this to enable restarting for job
sequence in this project.
Automatically handle activities that fail: Select this to have InfoSphere DataStage
automatically handle failing jobs within a sequence (this means that you do not
have to have a specific trigger for job failure). When you select this option,
the following happens during job sequence compilation:
For each job activity that does not have
specific trigger for error handling, code is inserted that branches to an error
handling point. (If an activity has either a specific failure trigger, or if it
has an OK trigger and an otherwise trigger, it is judged to be handling its own
aborts, so no code is inserted.)
If the compiler has inserted
error-handling code the following happens if a job within the sequence fails:
·
A warning is logged in the sequence log about the job
not finishing OK.
·
If the job sequence has an exception handler defined,
the code will go to it.
·
If there is no exception handler, the sequence aborts
with a suitable message.
Log warnings after activities that finish with status other than
OK: Select
this to specify that job sequences, by default, log a message in the sequence
log if they run a job that finishes with warnings or fatal errors or a command
or routine that finishes with an error.
Log report messages after each job run: Select this to have a status report for a
job logged immediately the job run finishes.
Remote Page
This page allows you to specify whether
you are:
Deploying parallel jobs to run on a USS
system OR
Deploying parallel jobs to run on a
deployment platform (which could, for example, be a system in a grid).

Logs Page
Use the Logs page to control how the jobs
in your project log information when they run. The Logs page of the Properties
window contains the following controls:
Auto-purge of job log – Enables automatic purging of job log
files. Auto-purging automatically prevents the job logs becoming too large. If
you do not enable auto-purging, you must delete the job logs manually. Use the
Autopurge action options to control how auto-purging works:
Up to previous – Specify the number of job runs to retain
in the log. For example, if you specify 10 job runs, entries for the last 10
job runs are retained.
Over – Purge the logs of jobs which are over
the specified number of days old.

Enable Operational Repository logging – Writes job logs to the operational
repository so that information is available to other components in the IBM®
InfoSphere™ Information Server suite. Use the Filter log messages options to
filter the information that is written.
·
To limit the number of informational messages written
to the operational repository for each job run, select Maximum number of ‘Informational’ messages that will be written to
the Operational Repository for a job run, and set a value for
this option. The default value is 10.
·
To limit the number of warning messages written to the
operational repository for each job run, selectMaximum number of ‘Warning’
messages that will be written to the Operational Repository for a job run,
and set a value for this option. The default value is 10.
Advance: Grid Page
For a project, set “Enable grid support
for parallel jobs” in the parallel page. Come back to General tab of InfoSphere
DataStage Administration dialog, you cans see Grid button being enabled. Click
the Grid to define master configuration file “master_config.apt”
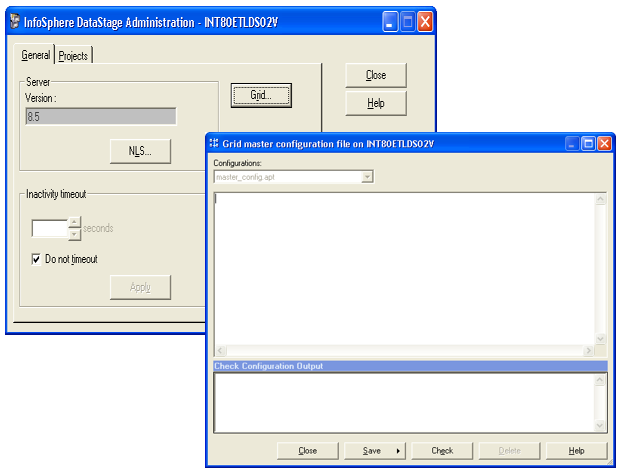
Voila!
That’s a very long post but I hope it is informative.

No comments:
Post a Comment